tl;dr
We reported a long standing PEAP bug in all Apple devices that would allow an attacker to force any Apple device (iOS, macOS or tvOS) to associate with a malicious access point, even if the authentication server (RADIUS) couldn’t prove knowledge of the password. To understand it fully, we go on a deep dive into EAP and MSCHAPv2.
Table of Contents
While prepping for our Defcon talk last year, Michael kept pushing me to implement hostapd-wpe‘s EAP success attack. In this attack, the authentication server will accept any username, then skip the step where it proves knowledge of the password back to the station (because it doesn’t know the password), and instead sends an EAP-success message back to the station. I refused for a long time, because I thought it was a dumb attack that would never work. This is because in MSCHAPv2 the authentication server also proves knowledge of the password back to the station, and if it couldn’t, I assumed the station would just refuse to continue, after all, that’s the whole point.
Eventually, I caved and tested hostapd-wpe’s “always send EAP success” attack against a few devices, and bizarrely, my Apple devices (iPads, iPhones, Macbooks) all successfully connected to the malicious access point. Huh?
Since WPE is written by Brad Antoniewicz, I asked him if he was aware of the bug, to which he replied:
So I wrote up a bug report and sent it off to Apple. It was a weird one, because Brad did the technical work that lead to discovery of the vulnerability, plus it had been a feature in hostapd-wpe for a few years already. The disclosure timeline and original report are at the end of this post.
To understand the vulnerability, we need to know how MSCHAPv2 in PEAP works and that requires a deep dive into some concepts. I’m writing them up and releasing the toy code to validate what I’m saying, because there are no good recent writeups of how this works, and how to see it for yourself.
PEAP at a High Level
The first “P” in PEAP stands for “Protected” and practically that means the whole exchange is wrapped in TLS. This part is called the outer tunnel. Within that tunnel, a MSCHAPv2 challenge response happens where the station (or the client, or the peer) and the authentication server (or RADIUS or AAA) prove knowledge of an identified user’s password to each other. This is done via the AP (because most often it isn’t also the RADIUS authentication server). If you’re familiar with wifi hacking, this is the part where if you person-in-the-middle it, you get the challenge:response hash to send to JtR/hashcat/asleap.
After this, the normal WPA/2 4-way handshake occurs. But, instead of using a typical pre-shared key, it uses a key (the pairwise master key or PMK) negotiated during the outer TLS session. This means, while you can capture these handshakes, you won’t be able to crack them.
MSCHAPv2
MSCHAPv2 is a challenge response protocol. The station and authenticator first identify themselves (to make sure that user is authorised). Then both share a random challenge (peer and authenticator challenge) which is combined with things like the username and password hash to prove to each other that they both know the password, without ever sending the password across the wire.
There are several RFCs that cover EAP, PEAP, CHAP, MSCHAPv1, MSCHAPv2, MPEE and MPEE key derivation. These are pretty frustrating to read as they refer to eachother, and no one document puts it all together. I did, in the code at https://github.com/sensepost/understanding-eap.
Decrypting the Inner Tunnel
This is typically where packet captures would come in. However, the whole MSCHAPv2 exchange is encrypted by TLS. Years ago, Michal wrote a perl script to decrypt this inner session and display it in Wireshark as well as documenting what was happening in the inner tunnel. However, modern TLS isn’t so easily decrypted thanks to perfect forward secrecy, and I wanted to see how things changed when we made the mana authenticator act differently. So instead, I told wpa_supplicant and hostapd to use the openssl eNULL cipher. This provides no encryption, only authentication of the data. Which means we can see the data in the clear. This, combined with the hexdump’s provided by hostapd-mana run with debugging (-d), let me see what was happening in the inner tunnel.
You can enable eNULL in wpa_supplicant and hostapd by adding the following line to the respective config (use quotes for wpa_supplicant’s config, no quotes for hostapd’s):
openssl_ciphers="eNULL"
The Inner MSCHAPv2 Exchange
A packet capture of a successful association looks like this:
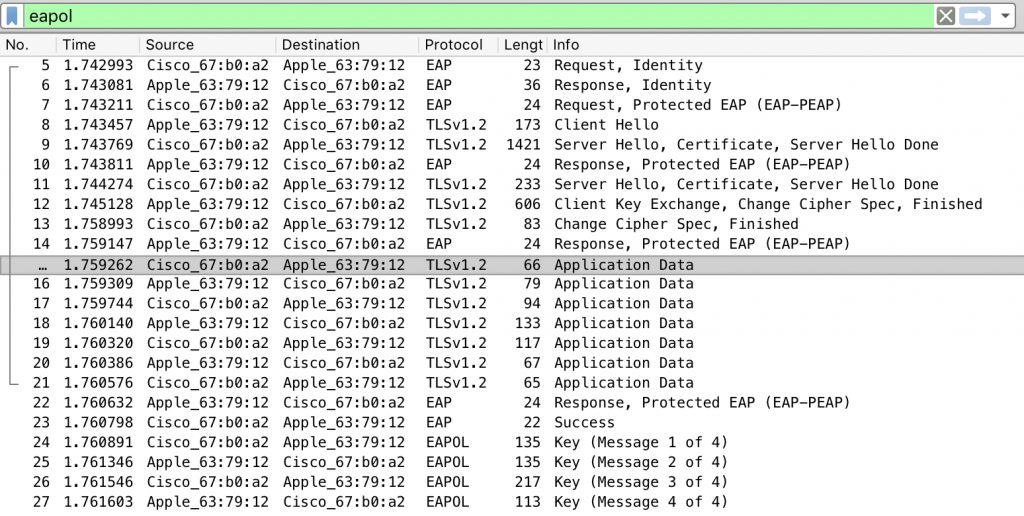
You can see the following happening:
- Frames 5-6: The authenticator asking the stations for it’s outer identity.
- Frame 7: Starting PEAP
- Frames 8-13: TLS initiation
- Frames 15-21: MSCHAPv2 in the inner tunnel
- Frames 22-23: PEAP and EAP end
- Frames 24-27: The WPA2 4-way handshake
As you can see the MSCHAPv2 exchange happens over seven frames. These are listed here, and the specific bytes described after:
- Authenticator -> Station – Initiation: let’s do this
- Station -> Authentication – Username: sure, this is my id
- Authenticator -> Station – Authenticator Challenge: nice, here’s my challenge and hostname
- Station -> Authenticator – Peer Challenge & NTResponse: cool, cool, here’s my challenge and I heard you like DES so I encrypted our challenges with the password hash as a key.
- Authenticator -> Station – Authenticator Response: I see your response, and raise you a sha1 hash of all of that with some static magic bytes from the RFC, oh and I double hashed the password for reasons
- Station -> Authenticator – Success
- Authenticator -> Station – Success: Me too
If you look at the encrypted data within the first frame, wireshark helpfully “decrypts” it for you:
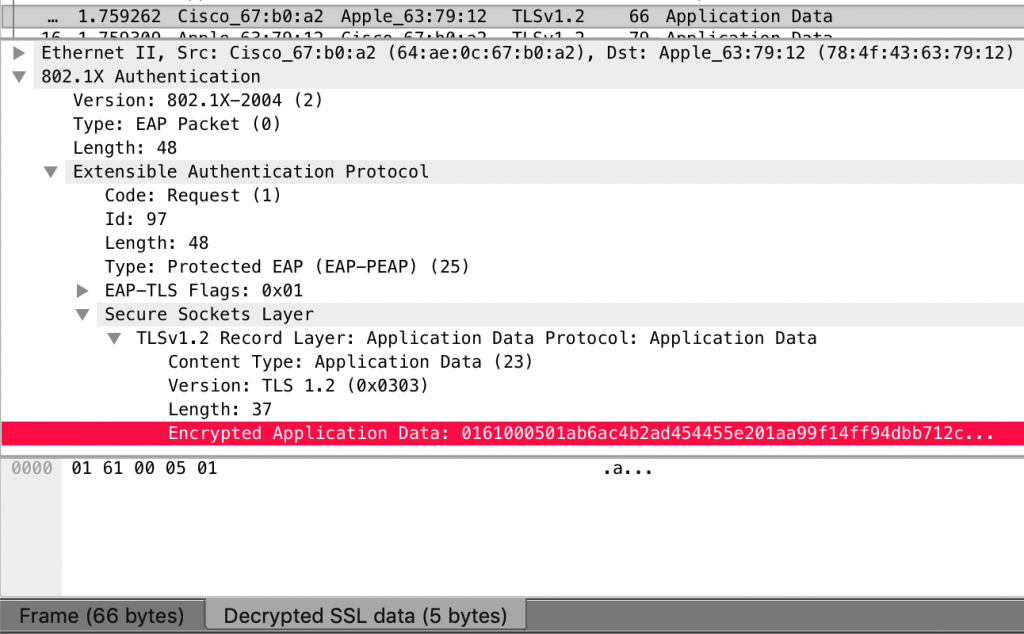
Byte-Level Description of the MSCHAPv2 Exchange
MSCHAPv2 Frame 1: Authenticator -> Station – Initiation.
This is a EAP/CHAP format, which is made up of the following. All bytes are in hex except where they conform to ASCII strings.
- Code: 01 – This is a challenge
- Identifier: 61 00 – This is the challenge’s ID
- Value-Size: 05 – aka length
- Value: 01
MSCHAPV2 Frame 2: Station -> Authentication – Username
- Code: 02 – This is a response
- Identifier: 61 00 – Response to Frame 1’s ID
- Value-Size: 12
- Value: 01
- Name: Oliver.Parker
MSCHAPV2 Frame 3: Authenticator -> Station – Authenticator Challenge
- Code: 01 – Challenge
- Identifier: 62 00 – Response to previous new ID
- Value-Size: 21
- Value: 1a – Seems to indicate start of a new CHAP frame
- Code: 01
- Identifier: 62 00
- Value-Size: 1c
- Length: 10 – Authenticator Challenge length
- AuthenticatorChallenge: f5 b8 ad ee e9 ff 08 15 dd 83 e8 2d 89 6e eb 2a
- Authenticator Name: hostapd
MSCHAPV2 Frame 4: Station -> Authenticator – Peer Challenge & NTResponse
- Code: 02
- Identifier: 62 00
- Value-Size: 48
- Value: 1a
- Code: 02
- Identifier: 62 00
- Value-Size: 43 – 67 in decimal
- Length: 31
- PeerChallenge: e3 32 bf 8e c5 37 e5 72 1d 0d 9a 0e e4 40 46 d6
- Padding?: 00 00 00 00 00 00 00 00
- NTResponse: 6c da db 80 dd 53 10 b8 05 f2 a0 da 9b b4 5e ad 51 ee 65 34 4c 95 e6 00
- Padding?; 00
- Name: Oliver.Parker
MSCHAPV2 Frame 5: Authenticator -> Station – Authenticator Response
- Code: 01
- Identifier: 63 00 – New Challenge ID
- Value-Size: 38
- Value: 1a
- Code: 03 – Success?
- Identifier: 62 00
- Value-Size: 33 – 51 in decimal
- AuthenticatorResponse: S=3EC7654786779579D27FCB870C93670D66E5AFB7 M=OK
MSCHAPV2 Frame 6: Station -> Authenticator – Success
- Code: 02
- Identifier: 63 00
- Value-Size: 06
- Value: 1a
MSCHAPV2 Frame 7: Authenticator -> Station – Success
- Code: 03 – Success
- Identifier: 64 00
- Value-Size: 04
MSCHAPv2 Calculations
We can check the above by implementing the code described in the RFC 2759 Section 8 which you can grab from our repo at https://github.com/sensepost/understanding-eap.
The Station/Client Side
Both the authenticator and the station send each other some random data (the challenges’s). The authenticator sends its challenge first (the Authenticator Challenge), so the client gets to kick off the computations. Using the values from above and the code I just posted, it looks like this from the python3 interpreter:
from eap import MSCHAPV2
UserName = b'Oliver.Parker'
Password='123456Seven'
AuthenticatorChallenge = b''.fromhex('f5 b8 ad ee e9 ff 08 15 dd 83 e8 2d 89 6e eb 2a')
PeerChallenge = b''.fromhex('e3 32 bf 8e c5 37 e5 72 1d 0d 9a 0e e4 40 46 d6')
chap = MSCHAPV2(UserName, Password, AuthenticatorChallenge, PeerChallenge)
PasswordHash = chap.NtPasswordHash(Password)
Challenge = chap.ChallengeHash(PeerChallenge, AuthenticatorChallenge, UserName)
NTResponse = chap.ChallengeResponse(Challenge, PasswordHash)
print ('Challenge : '+Challenge.hex())
print ('NTResponse: '+NTResponse.hex())
Challenge : ada74b1fca661d15
NTResponse: 6cdadb80dd5310b805f2a0da9bb45ead51ee65344c95e600
The station then sends the NTResponse and its peer challenge to the authenticator. You can see the calculated NTResponse matches that from frame 4 above.
A WPE interlude
That challenge and response should look familiar. It’s basically the same as a NetNTLMv1 hash. However, in NetNTLMv1 the challenge is just sent over the network, in MSCHAPv2 the challenge is computed from the two challenges and the username. This is also what freeradius-wpe, hostapd-wpe and hostapd-mana give you when they PitM (Person in the Middle) a PEAP session and capture a challenge response.
We can test this is correct using asleap/hashcat/JtR, I’ll use asleap:
> asleap -C ad:a7:4b:1f:ca:66:1d:15 -R 6c:da:db:80:dd:53:10:b8:05:f2:a0:da:9b:b4:5e:ad:51:ee:65:34:4c:95:e6:00 -W passwords
asleap 2.2 - actively recover LEAP/PPTP passwords. jwright@hasborg.com
Using wordlist mode with "passwords".
hash bytes: 2b6f
NT hash: 79337ad5724e777b41e8fc81ad232b6f
password: 123456Seven
And indeed, if we check the value of PasswordHash in our python, it will match asleap’s “NT hash”.
The Authenticator/RADIUS Side
At this point, the authenticator now has the stations challenge (the peer challenge) and can do similar calculations. They look like this:
from eap import MSCHAPV2
UserName = b'Oliver.Parker'
Password='123456Seven'
AuthenticatorChallenge = b''.fromhex('f5 b8 ad ee e9 ff 08 15 dd 83 e8 2d 89 6e eb 2a')
PeerChallenge = b''.fromhex('e3 32 bf 8e c5 37 e5 72 1d 0d 9a 0e e4 40 46 d6')
chap = MSCHAPV2(UserName, Password, AuthenticatorChallenge, PeerChallenge)
NTResponse = b''.fromhex('6c da db 80 dd 53 10 b8 05 f2 a0 da 9b b4 5e ad 51 ee 65 34 4c 95 e6 00')
PasswordHash = chap.NtPasswordHash(Password)
AuthenticatorResponse = chap.GenerateAuthenticatorResponse(Password, NTResponse, PeerChallenge, AuthenticatorChallenge, UserName)
print('Authenticator Response: ' + AuthenticatorResponse)
Authenticator Response: S=3EC7654786779579D27FCB870C93670D66E5AFB7
The authenticator then sends the authenticator response to the stations, along with a success or failure code. You can see that the calculated response matches that from frame 5 above.
MSCHAPv2 Failure Behaviour
In the case of a normal access point and authenticator, the station would send its username, and if the authenticator has a record for that user, authentication will continue. That failure condition isn’t particularly interesting.
However, if you set up a malicious authenticator, that will accept any username, you can capture the two challenges as well as the NTResponse from the station, which you can crack as detailed above. This was what Joshua Wright and Brad Antoniewicz published in 2008 with their initial freeradius-wpe work.
Interestingly however, the exchange ends, because the authenticator ended it, not the station. It can’t validate the NTResponse from the station (because it doesn’t have the right password). So the authenticator can’t compute an Authenticator Response, and instead sends a failure response in frame 5 along the lines of:
E=691 R=0 C=00000000000000000000000000000000 V=3 M=FAILED
WPE’s EAP-Success
In the case of WPE’s -s switch, to implement the “always return EAP-Success” attack, the authenticator skips sending the authenticator response, and jumps ahead to a success frame, much like frame 7 above.
If a normal station/client/supplicant sees this, it will end the exchange, because it was expecting the authenticator response. In wpa_supplicant’s case, it will hard stop and send a deauthentication frame at the AP.
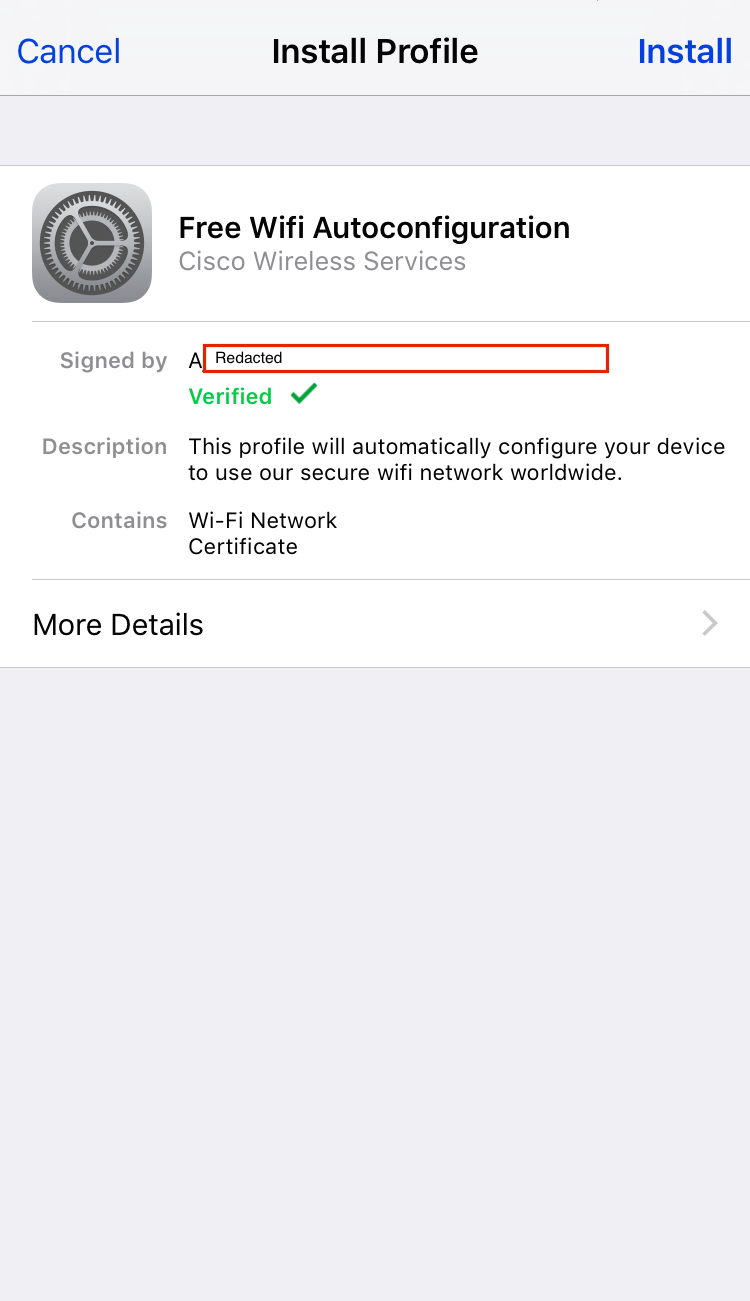
The Apple Vulnerability
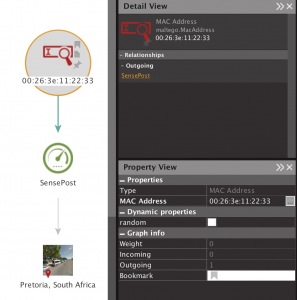
In the case of unpatched Apple devices, the authenticator would skip sending the authenticator response and just send a MSCHAPv2 success frame as per frame 7 above. A vulnerable Apple device happily jumps ahead in its state machine, accepts that, and exits out of the inner MSCHAPv2 tunnel. It then sends a PEAP response, to which hostapd-wpe sends the EAP-Success.
Earlier, when introducing PEAP, we said that by default (i.e,. if there’s no cryptobinding), the pairwise master key used for starting the WPA2 4-way handshake is taken from the outer TLS session. The authenticator sends this to the AP at this point, and the AP and Apple device happily complete the 4-way handshake and the device connects. Here’s an example:
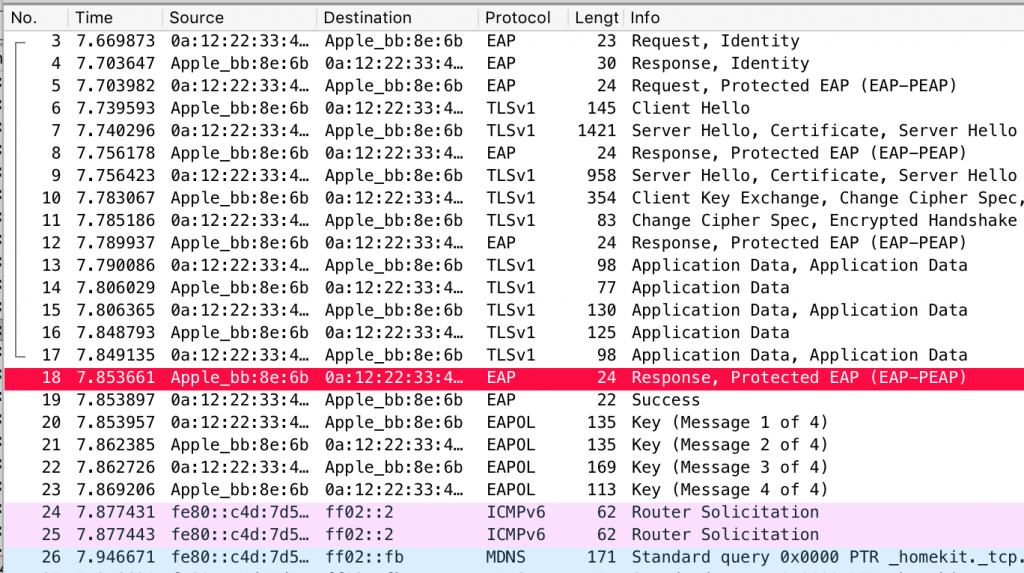
If you’d like to read the original vulnerability report, it’s at the bottom of this post.
The Risk
This means that if an Apple device connects to a rogue AP that doesn’t know the user’s password, not only will it get the NetNTLMv1 challenge response, the device will also connect to the network. Because EAP’ed networks are typically corporate networks, the Apple device will think it’s connected to that (sans user interaction), at which point Responder style attacks are also possible.
That said, this isn’t exactly CVSS 10 territory, and we rated the initial vulnerability as a CVSS3 5.5
However, the vulnerability seemed to affect multiple iOS and macOS versions, as well as multiple Apple devices such as Macbooks, iPhones and iPads. Apple’s advisory confirm it also affected Apple TVs.
Apple’s Fix
Apple released three updates for macOS, iOS and tvOS to fix this, and assigned it CVE-2019-6203. It took them approximately 8 months from the time of reporting to the fix. We don’t always appreciate the engineering effort that goes into fixing the vulns we fling at these teams, especially one that affects so many devices. A big thanks to anyone involved in getting it fixed.
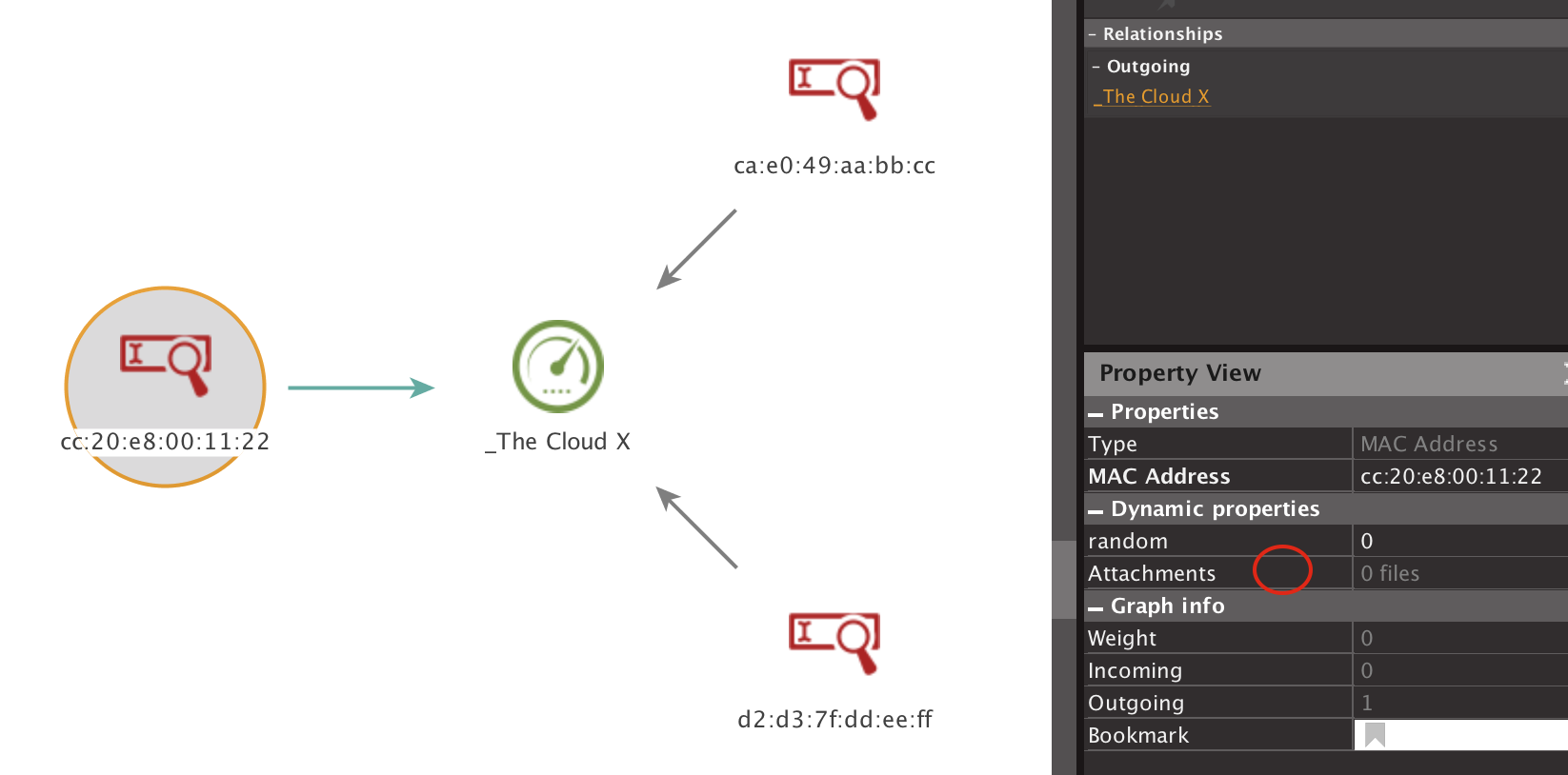
That said, the way Apple fixed this confuses me to no end. Devices that have been patched exhibit the exact same behaviour at a PEAP, MSCHAPv2 and WPA2 level i.e. the device still connects to the network, and in some cases will even request DHCP. Here’s an example:
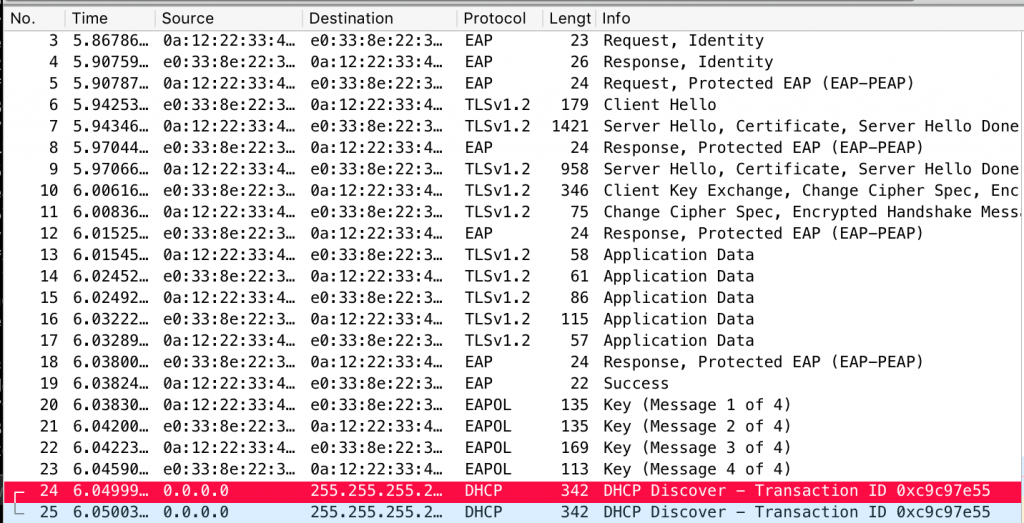
Instead, Apple made the devices disconnect from the network after connecting. The device displays a “cannot connect” error, and a log entry shows up on the device saying:

This is a little bit like a security guard letting someone in the building, then chasing them out once they’re inside. While it has the same end effect, I’d be a little worried about what could be exposed during that time. That said, different chips may be doing different things, and maybe this is a temporary fix until it can get fixed in firmware. I can only imagine it’s an engineering nightmare and wish the people dealing with it luck.
However, while testing the new fix, I did notice one outlier, when the device connected but derived a different PMK, evidenced by the MIC in the second message of the handshake. (That’s what the WPA code in the repo is for.) I haven’t been able to get it to repeat, but it should be impossible since the PMK is taken from the outer TLS session and cryptobinding wasn’t enabled. I also haven’t tested extensively across different devices. So there may be updates to my understanding of this fix later.
Disclosure Timeline & Details
- 2 Aug 2018 – Vulnerability report submitted
- 6 Aug 2018 – Akila @ Apple confirm receipt of 696428427
- 23 Oct 2018 – I asked for an update on progress
- 24 Oct 2018 – Akila said still investigating
- 4 Feb 2019 – I asked for progress update
- 6 Feb 2019 – Akila confirmed they will be addressing this in a future update.
- 6 Feb 2019 – I asked for an ETA
- 13 Feb 2019 – Akila said it won’t be getting a CVE
- 14 Feb 2019 – I asked why no CVE
- 20 Feb 2019 – Akila confirmed it will get a CVE after internal discussion
- 29 Mar 2019 – I saw the issue had been patched, but not disclosed in security notes.
- 2 April 2019 – Akila said will update security notes.
- 15 April 2019 – March 25 macOS, iOS and tvOS security notes updated. CVE-2019-6203 assigned.
I’d also like to thank the anonymous Apple employee who spoke to me off the record about progress.
While it’s lovely to see my name credited to this, Brad Antoniewicz deserves most of the credit as he wrote the initial exploit, I just spotted the specifics and reported it.
Original Vulnerability Report
Overview
iOS and macOS will connect to a malicious wifi access point using PEAP/MSCHAPv2 if an EAP-Success message is sent with an invalid authenticator MSCHAPv2 response.
Vulnerable Version
Only a few versions were tested, these were:
iOS 11.4.1 (iPhone)
iOS 9.3.5 (iPad)
macOS 10.13.6 (MBP Pro 2017)
Detail
PEAP establishes an outer TLS tunnel, and typically MSCHAPv2 is used within the tunnel to authenticate a supplicant (client iOS device) to an authenticator (backend RADIUS server). With MSCHAPv2 a challenge is sent to the supplicant, the supplicant combines this challenge and their password to send a nt-response. The authenticator generates the same expected nt-response based on its knowledge of the password, and compares them. If they match, an EAP-Success frame is sent to allow the supplicant to authenticate. However, this EAP-Success frame is sent with a 42-byte message authenticator based on the authenticator’s knowledge of the password (aka authenticator response). The supplicant should validate this message authenticator.
iOS and macOS do not. This makes it possible to stand up a fake access point, that will accept any username and password, and merely send an EAP-Success back. iOS/macOS devices will then connect.
wpa_supplicant on Linux and Android, and Windows 8/10 have been tested and are not vulnerable. As they will validate the message authenticator sent from the authenticator and refuse to connect.
Impact
CVSS3 5.5
https://www.first.org/cvss/calculator/3.0#CVSS:3.0/AV:A/AC:L/PR:N/UI:R/S:U/C:L/I:L/A:L
Devices could end up connected to networks the user believes are trusted. This could allow additional MitM attacks against the device or applications running on it.
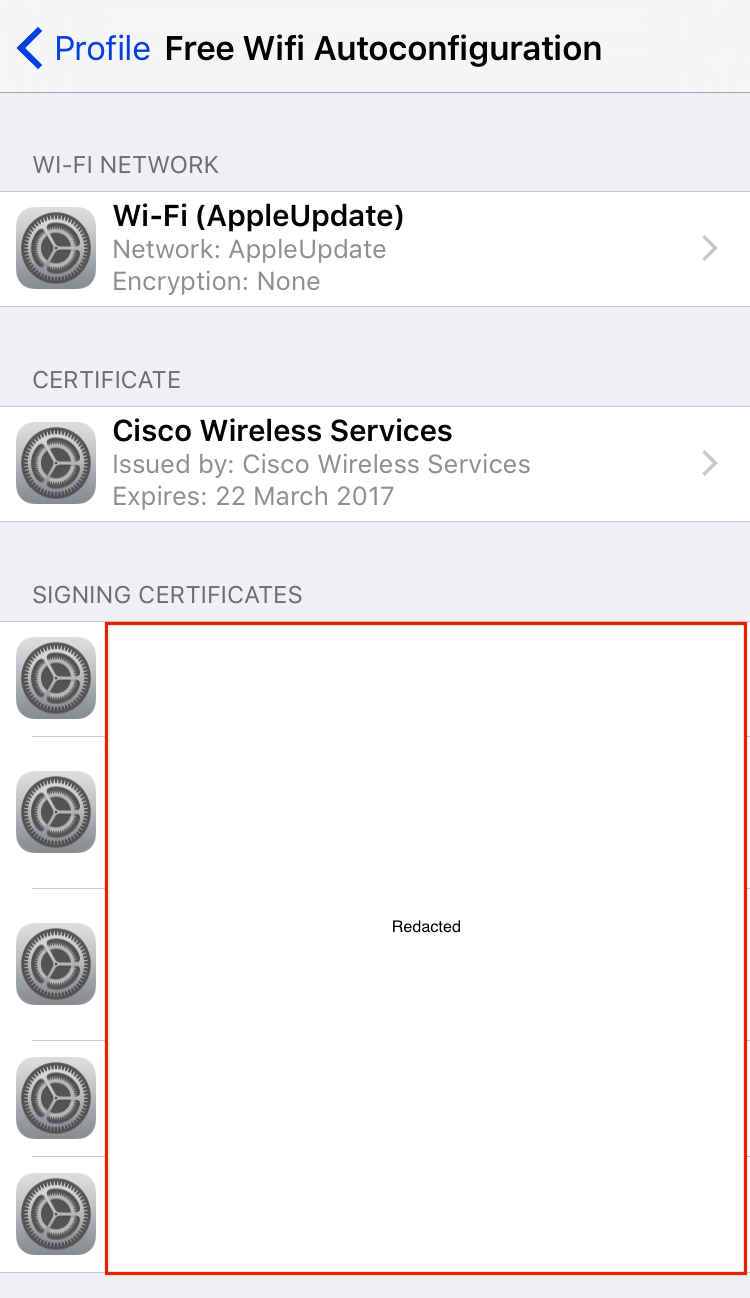
Devices connecting to PEAP networks should validate the certificate sent by the authenticator, but user’s aren’t good at validating certificates. However, iOS devices won’t automatically connect to the network if it has a different certificate, meaning users will need to manually select the network and choose to trust the new certificate. Although, cloning all aspects of the certificate with tools such as https://github.com/sensepost/apostille will make it hard for a user to differentiate a fake one from the original.
How to Reproduce
Install hostapd-wpe https://github.com/OpenSecurityResearch/hostapd-wpe/blob/master/hostapd-wpe.patch
This is most simply done in Kali with “apt-get install hostapd-wpe” and the following assumes that approach.
Run it with the -e switch to enable “EAP Success”
https://github.com/OpenSecurityResearch/hostapd-wpe/blob/master/README#L135
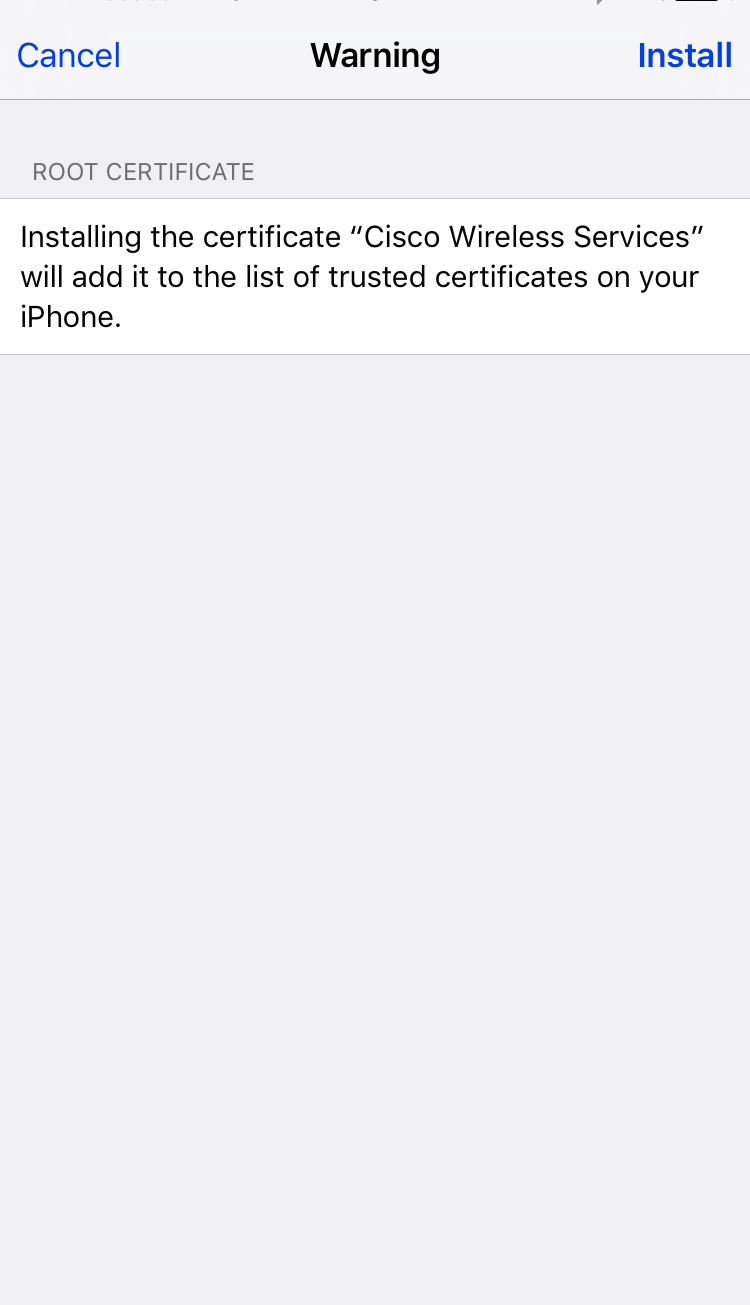
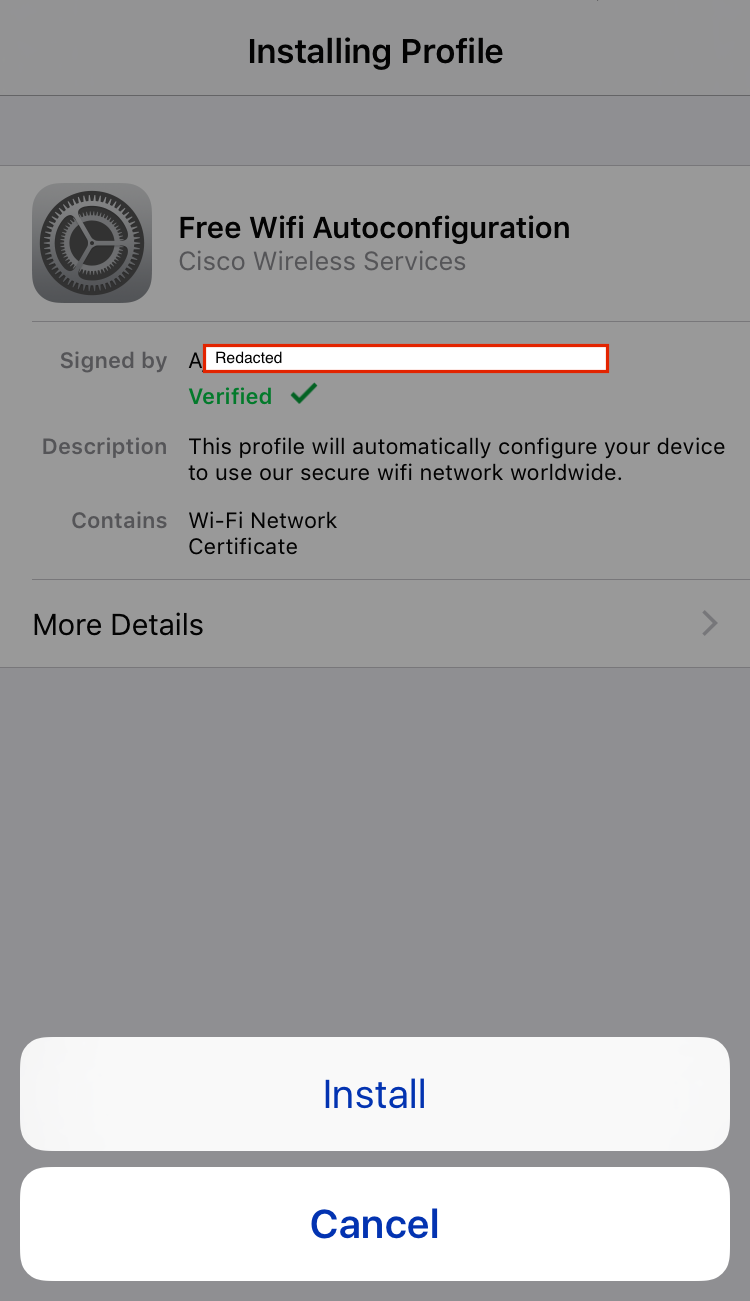
On an iOS device, under Wifi, connect to the “hostapd-wpe” network. Choose to trust the certificate. Any credentials can be used.
The device will connect. Running dnsmasq to hand out DHCP will show the device gets an IP.
Attempting the same client connection with wpa_supplicant using the following sample configuration will not work:
network={
ssid=”hostapd-wpe”
key_mgmt=WPA-EAP
eap=PEAP
phase2=”auth=MSCHAPV2″
identity=”test”
password=”password”
ca_cert=”/etc/hostapd-wpe/certs/ca.pem”
}
You will see the supplicant will reject the final message authenticator and disconnect.
Recommendation
Validate the message authenticator sent in the final EAP-Success message, and do not allow iOS/macOS device to connect to rogue access points that cannot prove knowledge of the user’s password.
An example of wpa_supplicant performing this validation can be found at:
https://w1.fi/cgit/hostap/tree/src/eap_peer/mschapv2.c#n112
Credit
Credit for the functionality I used goes to Brad Antoniewicz (@brad_anton) the author of hostapd-wpe. Although, he was not aware of the iOS/macOS specifics.
Originally published at SensePost's Blog. ]]>